Experimenting in mathematics to get a feel for what's what. Quantifying what you don't know.
Posted by: Gary Ernest Davis on: December 16, 2010
Easy to state, hard to solve, mathematics problems
Some easily stated mathematical problems are just too had for anyone currently to be able to solve.

Some outstanding examples are:
- Goldbach’s conjecture: every even number
is a sum of two prime numbers.
- the
conjecture: when we start with a positive integer and repeatedly apply one of the following two operations:
(1) if a number is even divide it by 2
(2) if a number is odd, multiply it by 3 and add 1
do we always end up with an answer of 1?
- The Tower of Hanoi problem with more than 3 pegs.
The problem is to show that the conjectured smallest number of moves to solve the puzzle is in fact smallest.
- Whether the fractional parts
of the powers of
are equi-distributed in the interval
![[0,1]](http://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=8E8778&s=0&c=20201002)
- Whether the base 3 representation of
always contains a 2 digit for
.
- Whether
for all
.
This inequality is the remaining obstacle in the proof of Waring’s problem – a famous and outstanding problem in number theory. So even very simply stated unsolved probe can have far-reaching consequences.
The digit 2 in the base 3 representation of
The problem of whether the base 3 representation of
Extensive calculations indicate it seems to be true, but those calculations have to end somewhere, and maybe, just a bit further along, there will be a power of 2 whose base 3 representation does not contain a 2 digit.
So apart from more calculations of powers of 2, conversion of them to base 3, and examining the digits for a 2, what else could we do? What other experimental evidence could we bring to bear on this problem.
A sensible technique to “mathematize” any problem is to count: to ask how many “whatevers” are there?
So, instead of asking is there a 2 digit in the base 3 representation of
The question has now changed from an existential question (“Is there a needle in this haystack?”) to a quantitative question (“How many needles are there in this haystack?”).
To address this question let’s count and use basic descriptive statistics.
In other words, let’s gather some data and do a little exploratory data analysis.
How many 2’s are there in the base 3 representation of ?
To calculate large powers of 2, convert to base 3, and count the digit 2, can be very time consuming.
This calls for a computational device.
A great programming language to do these calculations is Python.
But I’m not much of a Python programmer, not much of a programmer period, so I’m going to use a simple Mathematica program:
L = {};
Do[
A = IntegerDigits[2^n, 3];
L = Append[L, {n, Count[A, 2]}],
{n, 0, 10000}]
ListPlot[L, Joined -> True, PlotStyle -> {Blue}]
Here’s the resulting plot:

The number of occurrences of the digit 2 in the base 3 representation of 
Not only does the base 3 representation of
Let’s denote by 
How does 
Some calculations indicate that 
")
We might loosely imagine that the closeness of the blue portion of this plot to the red line tells us that for large enough 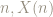
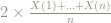

Rearranging this approximation we get:
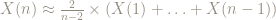
for 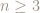
Statistically, we can think of this as:

for 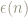
From a statistical point of view we want to know how is the error 
Below is a histogram of the error 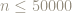
") This error distribution seems quite symmetric, with a mean of approximately 0, but quite “peaky” – more so than a normal distribution.
This error distribution seems quite symmetric, with a mean of approximately 0, but quite “peaky” – more so than a normal distribution.
The descriptive statistics for this distribution are:
mean = 0.0277584
stdev =59.0305
skewness = -0.0435969
kurtosis = 3.98242
So, indeed, the mean is almost 0, the distribution is quite symmetric, and the kurtosis is higher than that (3) for a normal distribution.
This is more like a logistic distribution.
As we alter the range over which we look at the error we get a distribution with a different variance.
For example, when we look at 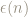
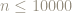
")
This has similar features to the distribution of
mean = 0.765212
stdev =26.2593
skewness = 0.0684994
kurtosis = 3.95492
How does the variance of 

Almost exactly linearly it seems:

Variance of for with varying from 1000 to 21000 in steps of 500
Variance of
What does this tell us?
This, of course, does NOT tell us that the base 3 representation of
However, it does induce a degree of confidence that not only is this true, but that we can see a good reason why it might be true: namely, the number of occurrences of the digit 2 seems to grow in a relatively orderly way with increasing
This is still a long, long way off an argument, but perhaps simple counting and basic exploratory data analysis might give us the germ of a productive idea to understand better how the digit 2 occurs in the base 3 representation of
Alongside proof, mathematics is beginning to utilize techniques of statistical analysis to obtain information about quantities of interest in mathematics.
Increasingly, statistics is being used to obtain information about mathematical quantities that previously were only analyzed in a Boolean way: either they existed or did not.
Hans Rosling's 200 Countries, 200 Years, 4 Minutes
Posted by: Gary Ernest Davis on: December 15, 2010
The video below shows a stunning example of Hans Rosling’s (@HansRosling) data visualizations using Gapminder software.
