Probabilities: when do we add and when do we multiply?
Posted by: Gary Ernest Davis on: October 27, 2010
 @davidwees asked on Twitter: “Looking for ideas so students can experiment with the difference between mutually exclusive & independent events in probability.”
@davidwees asked on Twitter: “Looking for ideas so students can experiment with the difference between mutually exclusive & independent events in probability.”
My Twitter response was: “May sound strange, but: when do probs add, when do they multiply? Explore.”
In this post I want to think about mutually exclusive and independent events from a teaching point of view.
One issue, as I Tweeted to @davidwees is that we have a definition of mutually exclusive other than probabilities add, but we have no definition of independent other than probabilities multiply (or something immediately equivalent: see the postscript, below).
So let’s look at a simple example where students might explore addition and multiplication of probabilities.
Tossing a coin and rolling a die
This example involves tossing a fair coin and rolling a fair die.
The elementary events are pairs 


We can lay out these elementary events in a table, as follows:
|
(H, 1) |
(H, 2) |
(H, 3) | (H, 4) |
(H, 5) |
(H, 6) |
|
(T, 1) |
(T, 2) |
(T, 3) |
(T, 4) |
(T, 5) |
(T, 6) |
There are 12 elementary events and so 
Let’s take the event A, consisting of pairs where the die rolls an even number, and the event B where the die rolls an odd number.
So we have:

and
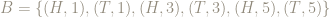
Is 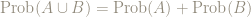
Yes, because 
Is 
No, because 
Here are 2 events, both of size 4, chosen at random from the elementary events:
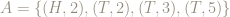
and

Is
No, because 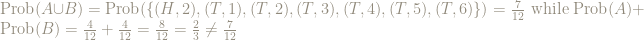
These events were chosen randomly using the folowing Excel commands:
| =IF(RAND()<1/2,”H”,”T”) | =INT(RAND()*6)+1 |
| =IF(RAND()<1/2,”H”,”T”) | =INT(RAND()*6)+1 |
| =IF(RAND()<1/2,”H”,”T”) | =INT(RAND()*6)+1 |
| =IF(RAND()<1/2,”H”,”T”) | =INT(RAND()*6)+1 |
x
When do probabilities add?
The answer of 

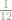

That 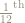

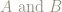
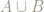
This situation is typical: any time 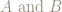
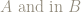
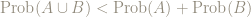
On the other hand, if 
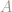

So, at least for the example above, 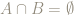
When do probabilities multiply?
When might we have 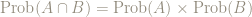
In the situation of our example, 
So:
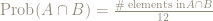
while

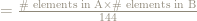
and we have

An example would be when 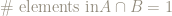
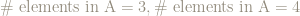
For example: 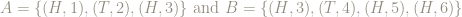
There are many other pairs of events

Student exploration
Because “independence” is a name given to events 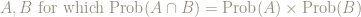
When students have many examples of this phenomenon, it then – and only then – makes sense to give it a name: “independence”.
To first define “independence” in terms of
Postscript
Many Tweeps, and some commentators, have opined that the basic way of expressing independence is 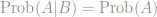
This is fine if one knows what is 
An answer such as “The probability that A happens given that you know B has happened” is not very helpful in actually calculating probabilities.
For that one needs a more precise definition and the usual one is 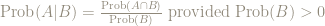
One can then define independence by 
Conditional probabilities are, in my experience, quite difficult for students of all ages to get their heads around.
If someone can suggest a series of explorations that assist high school students to become comfortable working with conditional probability then that would, of course, be another route to independent events.
If you have such explorations, or know of them, I would be very glad to hear of them, as would the mathematics teachers whose questions prompted this post.
Sharing such knowledge about the learning and teaching of mathematics is what the Republic of Mathematics is all about.
An example that illustrates – to me at least – how thorny are both conditional probability and independence for students comes from geometric probability.
Suppose we consider measurable subsets of a unit square ![S=[0,1]\times [0,1]](http://s0.wp.com/latex.php?latex=S%3D%5B0%2C1%5D%5Ctimes+%5B0%2C1%5D&bg=ffffff&fg=8E8778&s=0&c=20201002)
Define a probability measure on such sets by area: 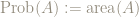
Now consider the following two sets ![A=[\frac{1}{2},1]\times[0,\frac{1}{2}], B=[\frac{1}{4},\frac{3}{4}]\times [\frac{1}{4},\frac{3}{4}]](http://s0.wp.com/latex.php?latex=A%3D%5B%5Cfrac%7B1%7D%7B2%7D%2C1%5D%5Ctimes%5B0%2C%5Cfrac%7B1%7D%7B2%7D%5D%2C+B%3D%5B%5Cfrac%7B1%7D%7B4%7D%2C%5Cfrac%7B3%7D%7B4%7D%5D%5Ctimes+%5B%5Cfrac%7B1%7D%7B4%7D%2C%5Cfrac%7B3%7D%7B4%7D%5D&bg=ffffff&fg=8E8778&s=0&c=20201002)

Then 
Is this any more or less intuitive than 
How much does that glass of wine cost?
Posted by: Gary Ernest Davis on: October 27, 2010
 About to ? Say, with tip?
About to ? Say, with tip?
No: the answer depends on how old you are when you drink it, and what you would do with the money otherwise.
I was watching a recent Suze Orman show and I admired the way she drove home the real cost of spending by relating it to a single everyday item.
Here’s my take on her message.
Suppose a young person spends 0 each month on entertainment which amounts mainly to drinking in clubs and bars. This was, in fact, the figure quoted by the young man on the Suze Orman program.![]()
Over a working lifetime from 21 to 67 years of age this amounts to over a – staggering – $220,000 on alcohol.
But the financial cost is actually much greater.
Suppose the $400 each month is invested instead in a Roth IRA with an annual return of 8% per annum.
At age 67, after years of investing $400 each month from the age of 21, the accumulated savings amount to $2,290,000: tax free.
 These are today’s dollars, so we have to think about inflation. Currently that’s low, but it might, and probably will, rise in the future. By the same token the return on the Roth IRA will also likely rise as inflation rises.
These are today’s dollars, so we have to think about inflation. Currently that’s low, but it might, and probably will, rise in the future. By the same token the return on the Roth IRA will also likely rise as inflation rises.
So let’s say a 21 year old does not put $400 each month into a Roth IRA but spends that $400 on alcohol until, at the age of 30, they decide to change their ways and start saving for their retirement.
Now the $400 each month in the Roth IRA is being invested for 9 less years. Not so bad, you think: this person is still young.
The accumulated savings from 30 to 67 yeas of age is now $1,087,000: again, tax free.
By drinking for 9 years the young person has lost over 1,200,000 tax free dollars.
The drinks in those 9 years cost $43,200.
So a drink that, on the face of it, costs $10 with tip in that person’s 20s, in fact cost them over $278 in lost savings.
The $10 drink effectively costs $278.
That’s the price you are really paying when you are young.
Just one more reason, by the way, that G.V. Ramanathan is wrong: quantitative literacy is important for everyone.
