Phat metrics: read the labels, do the math
Posted by: Gary Ernest Davis on: September 25, 2010
When you are on a weight loss or weight management program, you are usually asked to carry out measurements to see how you are doing. These measurements might include the number of calories you eat each meal, the time spent exercising each day, the size of your belly, and your weight.
If things are not going as well as you would like, taking these measurements can be disheartening, even downright depressing, and you can easily feel guilty. That’s a bad thing, because guilt feels bad, and in order to feel good, we’re likely to eat something that makes us feel better. Now, we’re putting on the pounds and feeling doubly bad, and feeling like a failure.

If only things were this good!
However, if you want to manage your weight it is important to use sensible metrics. What is a “metric”? It is something measurable. Examples of metrics relevant to weight management are calorie intake, minutes of exercise, belly size, and weight, just the sort of things that many weight loss and weight management programs get us to measure. Metrics are important because they give us a reality check on how we are doing.
However, you should never, ever, be a slave to a metric. You should use metrics as your servants – faithful, truthful, reliable servants, but servants nonetheless.
Food manufacturers already provide us with useful metrics, by law. In your food store pick out a favorite food – one in a package – and look at the label. I’m going to use Ranch dressing as an example. My wife and stepson like Ranch dressing, and I’ve grown to like to too. We use it on salads:

In summer we typically make salads from iceberg lettuce, darker leaf lettuce, broad leaf parsley, green onions, red onions, tomatoes, radicchio, mint, spearmint, goat cheese, and boiled eggs. A little Ranch dressing mixed in with these vegetables is delicious.
So what’s on the label of a bottle of Ranch dressing ?
The brand we use is Litehouse Homestyle Ranch dressing and dip.

On the back of the bottle is a label which has the following information, and more:
√ Made Fresh √ No Preservatives √0g Trans Fat
√No MSG √100% Canola Oil √Guaranteed Delicious

That’s a lot of information. Some of it is metric information, and some is not. For example, the statement “Guaranteed Delicious” may be true (I happen to think it is) but it is not the result of a measurement – it might result from a number or people trying the dressing and saying that it is delicious, but the result is not reported as a measurement. If the label said “95% of people say it is delicious”, that would be the result of a simple measurement – counting how many people out of a sample of unknown size said the dressing was delicious. As it stands “Guaranteed Delicious” is not reported as the result of a measurement.
The statement “0g Trans Fat” is the result of a measurement. The manufacturer states that they have measured the amount of trans fat in the dressing and found no more than 0.5 g of trans fat – that’s what the “0” means in this context: not necessarily zero, but close enough. What is “0g”? The “g” stands for “grams” – a unit of measurement in the metric system. Notice how much of the metric information is reported in the metric system (kind of curious given that we’re looking for useful metrics!). There’s about 28 grams to an ounce (click here for a metric conversion calculator), but the important thing if you are concerned about trans fat is there is nor more thasn 0.5 g of trans fat. It doesn’t matter if you measure in grams or ounces, the manufacturer is telling you there is very little trans fat in this product.
Notice that I wrote “if you are concerned about trans fat”. You probably should be concerned about trans fat, but remember that we are not looking for metrics that enslave us – we are looking for metrics that are our faithful, truthful, reliable servants. You may not be so concerned about trans fats when you read the label. I wasn’t. I was glad to see there was no trans fats, but if the label had said “2g Trans Fat” I may still have bought the dressing: that’s my decision, no one else’s apart from my wife and stepson who will also be eating the dressing. My concern at the time I bought the dressing was carbohydrates. I noticed it had a low “2 g”. That’s 2 grams per serving, and the label also says there’s 13 servings in a bottle. The bottle says there’s 13 ounces of dressing in all, so that gives about 2grams of carbohydrates per ounce – or about 1/14th of an ounce of carbohydrates per ounce of dressing. Not much – it’s pretty low in total carbs. Because that is what I have been using as a metric – I want to keep my carb intake low – I was happy to use the Litehouse Ranch dressing.
There’s a lot of metric of information on the Ranch dressing label – measurements of vitamin content, sodium, protein, sugars, among others. I didn’t buy the dressing as a source of vitamins or protein – I bought it to flavor the salad I had made. So I was mainly concerned about the amount of carbs, the presence of nasty things like trans fat, and the fact that it was made using only canola oil. The carb metric is one of my faithful, reliable, truthful servants, and it informed me that, on the basis of that measurement, this dressing was possibly a good choice. If the dressing had been high in carbs I simply would not have bought it.
That is an example of how phat metrics – good metrics – are already out there for us to use in our plans to manage our weight. We do not have to obsess about every measurement, every detail, but focus on those aspects of food that can be measured that we deem to be relevant . It’s our life, our weight, and our bodies. We decide as intelligent people what we will eat and why.
Let appropriate metrics – phat metrics – be your guide, and your faithful servants. Liberate yourself by using appropriate metrics – ones that are useful to you and that do not enslave you, but help you achieve what you want because they are faithful, honest, reliable indicators.
Central ideas of school mathematics: Algorithmic thinking
Posted by: Gary Ernest Davis on: September 22, 2010
This is the second in a series of posts on central ideas of school mathematics, prompted by a joint project with my colleague Robert Hunting. Issues discussed here are ideas that I see as central to school mathematics if that subject is to avoid total disconnection with the rapidly changing world of professional and applied mathematics. [First post, on patterns]
Algorithmic thinking
I use the phrase “algorithmic thinking” rather than “algorithms” because I want to emphasize the cognitive aspects of engaging with algorithms, their implementation, and analysis.
Brief history
The word algorithm refers, in broad terms, to a mechanical procedure to carry out a process.
The origin of the word is an Anglicization of the Latin form of the name of the Persian scholar AbÅ« Ê¿AbdallÄh Muḥammad ibn MÅ«sÄ al-KhwÄrizmÄ«.
Al-KhwÄrizmÄ« wrote on methods for manipulating fractions that had been invented by Indian mathematicians. About 300 years after he wrote this work it was translated into Latin in the 
Al-KhwÄrizmÄ«’s account of the Hindu method of manipulating fractions was regarded as making simple and mechanical what was previously a relatively difficult calculation with ratios.
Long before Al-KhwÄrizmÄ«, the Greek mathematician Euclid described a mechanical procedure, which if followed faithfully, would find the greatest common divisor of two positive whole numbers. We now call this Euclid’s algorithm (or the Euclidean algorithm).
Algorithms have become increasingly important in modern life. Algorithms are used extensively in mathematics, engineering and science. The systematic study of algorithms in general (not necessarily numerical or geometrical algorithms) is what computer science is largely about.
Comprehending and using algorithms
In school mathematics algorithms are usually taught as something for students to comprehend and practice. At best this gets students familiar with an algorithm. At worst, it has students behaving like machines, instead of thinking human beings.
A very simple algorithm is the bisection algorithm for finding a zero (or root) of a function. This can be used to approximate specific numbers. For example, suppose we want to get a decimal approximation to 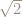
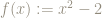

Plot of the function f(x)=x^2-2
We can see visually that the number we seek to approximate,
We can also figure this numerically because 
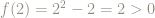
The bisection method works, iteratively, as follows:
- At each step we have an interval of numbers [L,R] such that
and
;
- We check the midpoint
to see if
is zero, negative or positive;
- If
we are done, and
is the number we seek [This cannot happen with
and
because
- If
 we set
and begin again with the new interval of numbers
.
- If
 we set
and begin again with the new interval of numbers
We continue this process until we find an exact answer (which, as explained above in the case of
When students in school are introduced to the bisection algorithm they will typically get a teacher led explanation of the mechanics of the algorithm and then get to practice how it is implemented in several examples. This will probably be followed with homework and a quiz or test of the same type of activity.
So a student would calculate (but usually not write as expansively about the process) as follows:
- Begin with the interval
where
and
.
- The midpoint is
and
so the new interval is
.
- The new midpoint is
and
so the new interval is
.

When we repeat this process a number of times we get the following sequence of intervals, whose endpoints (left or right)are successively better approximations to
[1, 2]
[1, 3/2]
[5/4, 3/2]
[11/8, 3/2]
[11/8, 23/16]
[45/32, 23/16]
[45/32, 91/64]
[181/128, 91/64]
[181/128, 363/256]
[181/128, 725/512]
[181/128, 1449/1024]
[181/128, 2897/2048]
[181/128, 5793/4096]
[11585/8192, 5793/4096]
[11585/8192, 23171/16384]
[11585/8192, 46341/32768]
On the other hand it is hard to see by visual inspection alone that these exactly calculated fractions are getting closer together, and so approximatingÂ
[1, 2]
[1.000000000, 1.500000000]
[1.250000000, 1.500000000]
[1.375000000, 1.500000000]
[1.375000000, 1.437500000]
[1.406250000, 1.437500000]
[1.406250000, 1.421875000]
[1.414062500, 1.421875000]
[1.414062500, 1.417968750]
[1.414062500, 1.416015625]
[1.414062500, 1.415039063]
[1.414062500, 1.414550781]
[1.414062500, 1.414306641]
[1.414184570, 1.414306641]
[1.414184570, 1.414245605]
[1.414184570, 1.414215088]
Now we can calculate the squares of the endpoints of the intervals to see if they are getting closer to 2:
[1, 4 ]
[1.000000000, 2.250000000 ]
[1.562500000, 2.250000000 ]
[1.890625000, 2.250000000 ]
[1.890625000, 2.066406250 ]
[1.977539063, 2.066406250 ]
[1.977539063, 2.021728516 ]
[1.999572754, 2.021728516 ]
[1.999572754, 2.010635376 ]
[1.999572754, 2.005100250 ]
[1.999572754, 2.002335548 ]
[1.999572754, 2.000953913 ]
[1.999572754, 2.000263274 ]
[1.999917999, 2.000263274 ]
[1.999917999, 2.000090633 ]
[1.999917999, 2.000004315 ]
So we can see that after 14 or so iterations, the estimates look accurate to about 4 decimal places.
Students, will, of course, generally find such calculation very tedious to do accurately, so it’s time to think about another important aspect of algorithms:
Machine implementation
Algorithms by their very nature are designed to be implemented on machines, to avoid excessive calculation by humans. A critical aspect of engagement with algorithms in school mathematics is how to implement an algorithm on a machine.
The numerical results above were calculated in Mathematica. Typically school mathematics classrooms do not have access to Mathematica. What’s even more limiting, many, if not most, mathematics teachers and classes do not have easy access to computers.
What mathematics teachers do usually have access to is calculators. If those calculators are programmable then the bisection algorithm, above, can be programmed into the calculator, which then does all the numerical calculations. If student calculators are not programmable. students can use calculators to get decimal approximations step by step. However, the very act of programming a machine to carry out the algorithm already leads to higher order thinking about the algorithm and helps embed into student memory what it is that the algorithm does.
Here is how I implemented the bisection algorithm to approximate
f[x_] := x^2 – 2;
L = {{1, 2}};
Do[
m = (L[[-1]][[1]] + L[[-1]][[2]])/2;
If[f[m] < 0, L = Append[L, {N[m, 10], N[L[[-1]][[2]], 10]}],
L = Append[L, {N[L[[-1]][[1]], 10], N[m, 10]}]],
{k, 1, 15}];
L
Whichever way the bisection method is implemented it will contain a loop ( a “do” loop or a “while” loop) and an “if” statement. With access to computers, students can implement the bisection algorithm in a spreadsheet.
Machine errors
Computers and calculators do not represent decimal numbers exactly. They cannot: even a number as simple as 
As an iterative process such as the bisection method proceeds, the decimal numbers it uses are only approximations to the exact fractions it could use. Calculation machine errors can, and will, spread as the iteration proceeds.
To address this issue with students, some sort of check as to the accuracy of the results needs to be carried out.
In the calculations above we squared the decimals to see if the result was close to 2. This squaring process again involves approximations and errors, but at the very least, it can provide reassurance that the errors are not spreading too badly.
Discussion of, and reflection on, possible machine errors in calculation is an essential part of a modern way of thinking about calculations. It is one part of the central idea of algorithmic thinking.
Speed
Another modern focus in algorithmic thinking is speed: if an algorithm such as the bisection method to approximate
Students can get a visual feel for the speed of convergence to a solution by plotting successive left and right hand approximations:

Plot of left hand (bottom) and right hand (top) approximations to square root of 2
We can expand this plot around 1.4 (from 1.35 to 1.45):
 The plots give visual reinforcement to the feeling that the bisection method to approximate
The plots give visual reinforcement to the feeling that the bisection method to approximate
Why do we worry about speed of convergence?
Basically for two reasons:
- The time the algorithm takes to run to get a desired degree of accuracy might be excessively long, on the order of days or months for some algorithms, compared with minutes or seconds.
- The longer an iterative algorithm runs the more it runs the risk of spreading machine errors to the point it is highly inaccurate.
The theoretical error – as opposed to machine calculated error – in using the midpoint of the previous interval as an approximation to ![[L,R]](http://s0.wp.com/latex.php?latex=%5BL%2CR%5D&bg=ffffff&fg=8E8778&s=0&c=20201002)


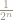
This is a good motivation for base 2 logarithms, because if we want an error of no more than size 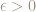
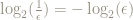
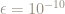
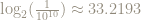
Correctness
How do we know an algorithm does what we expect it to do?
This is an obvious and important question that is central to modern thinking about algorithms, yet is probably never addressed in school mathematics, and only rarely in university or college (usually in more advanced discrete mathematics courses, or computer science courses).
Checking that an algorithm is correct is not often an easy task, and sometimes it is quite hard. Yet the issue is relatively simple: what reasoning can we bring to bear on why a particular algorithm does what it is supposed to do?
A school student answer might not be as sophisticated as a college student, or as a graduate student or as a professor of mathematics or computer science. Yet that is no reason to avoid addressing the issue of correctness.
How might we, informally at least begin to address the correctness of the bisection method?
This is an unusual activity for school mathematics (although a central one, I claim) because it involves thinking.
- At each step of the bisection algorithm to approximate
- From this interval we calculate the midpoint
and check the value
- If
by
by
- The new interval is contained in the previous interval.
- The size of the interval goes down by
at each step.
- So we construct a decreasing sequence of closed intervals whose size halves at each step and therefore approaches 0 as the number of steps increases.
- The monotone convergence theorem – an intuitively obvious statement about a geometric interpretation of decimal numbers -Â says that the left hand points of the intervals converge to a number
and the right hand endpoints converge to a number
.
- Since the distance between the left hand and right hand endpoints approaches 0,
- Because
is a continuous function – it operates on nearby numbers to produce nearby numbers -Â
, that is
.
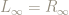
Fragments of this – informal – argument can be used to heighten a student’s sense of proving a reason why the algorithm does what it is supposed to do, through utilizing geometric properties of real numbers as decimals.
Moral
Algorithmic thinking, as distinct from students simply practicing hand implementation of algorithms, is a central idea of school mathematics because of the centrality of algorithmic thinking in mathematics, engineering and science.
Important aspects of engagement with algorithmic thinking are:
- Comprehending an algorithm
- Hand implementing an algorithm
- Machine implementing an algorithm
- Reflecting on and estimating machine errors
- Reflecting on and estimating theoretical errors
- Reasoning about correctness
And after all that we have not yet touched on another important aspect of algorithmic thinking, one that the National Council of Teachers of Mathematics stresses:
- Generation of new algorithms
Algorithmic thinking needs to be critically addressed in school mathematics at the highest policy levels if school mathematics is not to become increasingly disconnected from, and irrelevant to, modern mathematical practice and concerns.
Postscript
There’s an interesting discussion at reddit.com on what algorithm blows your mind.
