Some fun with a (very) simple matrix
Posted by: Gary Ernest Davis on: February 20, 2011
Geometry of a transformation
The 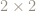
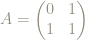
As a 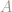
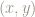
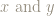
The matrix 

We can look at what the matrix
For example, the square with corners 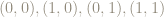
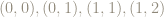
 The area of the parallelogram is 1 unit – the same as the area of the original square. Because area of any plane figure is based on counting squares – and taking a limit with vanishingly small squares if the figure is somewhat round, such as a circular region – the matrix
The area of the parallelogram is 1 unit – the same as the area of the original square. Because area of any plane figure is based on counting squares – and taking a limit with vanishingly small squares if the figure is somewhat round, such as a circular region – the matrix
However if we imagine traveling counter-clockwise from the point 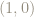


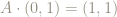

In other words, the matrix
Appearance of the Fibonacci numbers
What happens when we apply the matrix over and over to a point?
For instance, if we apply the matrix 
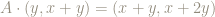
This is the same result as if we had applied the square 
This is true more generally: to figure out what applying the matrix
So can we characterize, or identify, the powers of the matrix
Here are the first few powers:

x
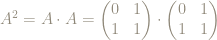
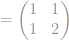
x

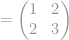
x
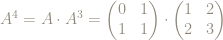
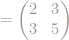
x


These matrix entries are looking suspiciously familiar: they are looking like the Fibonacci numbers
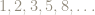
Have we just been lucky so far, or is this something we can prove?
A good proof technique for this sort of problem is proof by induction, because we know inductively how to work out the powers of the matrix 
First, we need a precise statement of what it is we are trying to prove.
It’s looking like:
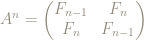


x
This is certainly true for 
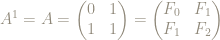
So let’s suppose that it’s true for some particular value of 

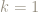
Then
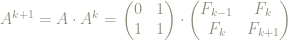
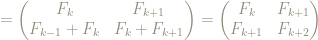
so our statement is true also for 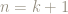

Moving to a torus
The matrix 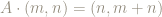
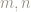
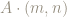
This means we can restrict
For example, the point 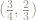
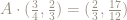

This operation, of reducing coordinates by keeping only the fractional parts is called reduction modulo 1.
Wwe write the result of keeping only the fractional parts of the coordinates of the point

When we think about this for a moment we see that some apparently different points on the unit square are actually the same, modulo 1.
For example, any point of the form 
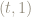
Ditto, any point 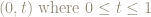
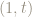
This means the sides of the squares, are really the same line, modulo 1:
 We can get a different picture of the unit square, modulo 1, if we glue together points on the square that are the same modulo 1.
We can get a different picture of the unit square, modulo 1, if we glue together points on the square that are the same modulo 1.
First we can glue corresponding points on the blue sides to get a cylinder:

Now, when we glue together the red ends of the cylinder, as indicated, we get the surface of a donut, otherwise known as a torus:

So now we can use the matrix
What happens if, for example, we begin with the point 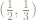

x
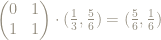
x

x

x
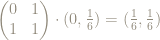
x

x

x
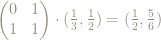
x

x
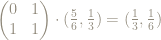
x
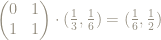
x

x
and we are back to where we started, after 13 steps.
The collection 12 points we collected along the way: 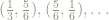

Any of the points in the orbit of
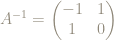
Just as for the point we chose, any point on the torus with rational number coordinates will have a finite orbit.
Question 1: Can you see why this is so?
Question 2: Can you figure out the size of the orbit of the point 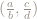
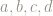
Wherever we are on the torus there is a point nearby – as close as we wish – that has rational coordinates. Therefore, wherever we are on the torus there is a point nearby – as close as we wish – with a finite orbit.
Arnold’s cat map
The square of the matrix 
This matrix gives us an area-preserving, orientation-preserving transformation of the torus, that like the matrix
What this means in practice is that when we take two points on the torus that are very close together, and examine points in their orbit we will soon find corresponding points that are quite far apart.
Then as we progress through the orbits we will find the points get back close together again.

Vladimir Arnold
Vladimir Arnold visualized this by imagining a picture of a cat drawn on the torus and seeing what happened to the cat as we repeatedly applied the matrix transformation .
The cat would at first get spread all over the torus but would eventually become almost reconstructed.
A lovely account of Arnold’s cat map appears in the article “Period of a discrete cat mapping” by Freeman Dyson and Harold Falk.

Leave a Reply